Hi, my name is Billy. This is where I try to archive topics related to Applied Data Science & ML.
Needfinding, and why knowing the fix is the easy part.
What changed in how I work after handing real tasks to a terminal coding agent, and what it replaced.
Why Anthropic leans on XML tags. Following the thread from prompt formatting down to how self-attention was trained.
How large would an unobserved confounder need to be to overturn your causal estimate? A survey of methods for bounding omitted variable bias.
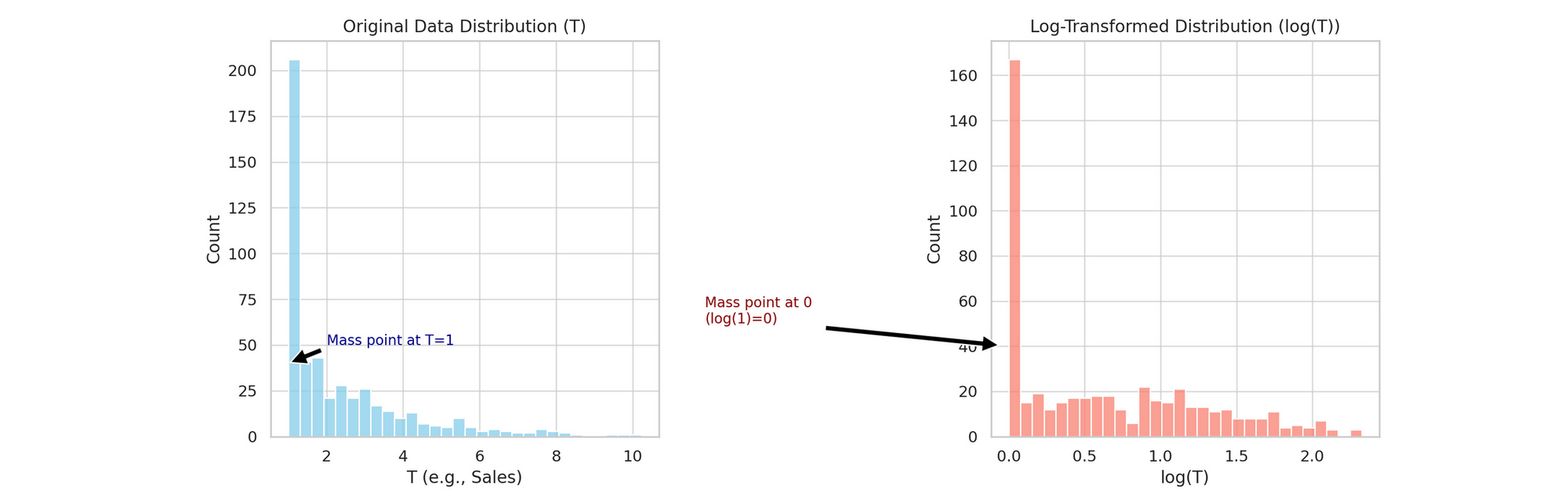
A mass point (a big cluster of identical values) can wreck linear regression after a log transform. Why it happens and what it breaks.
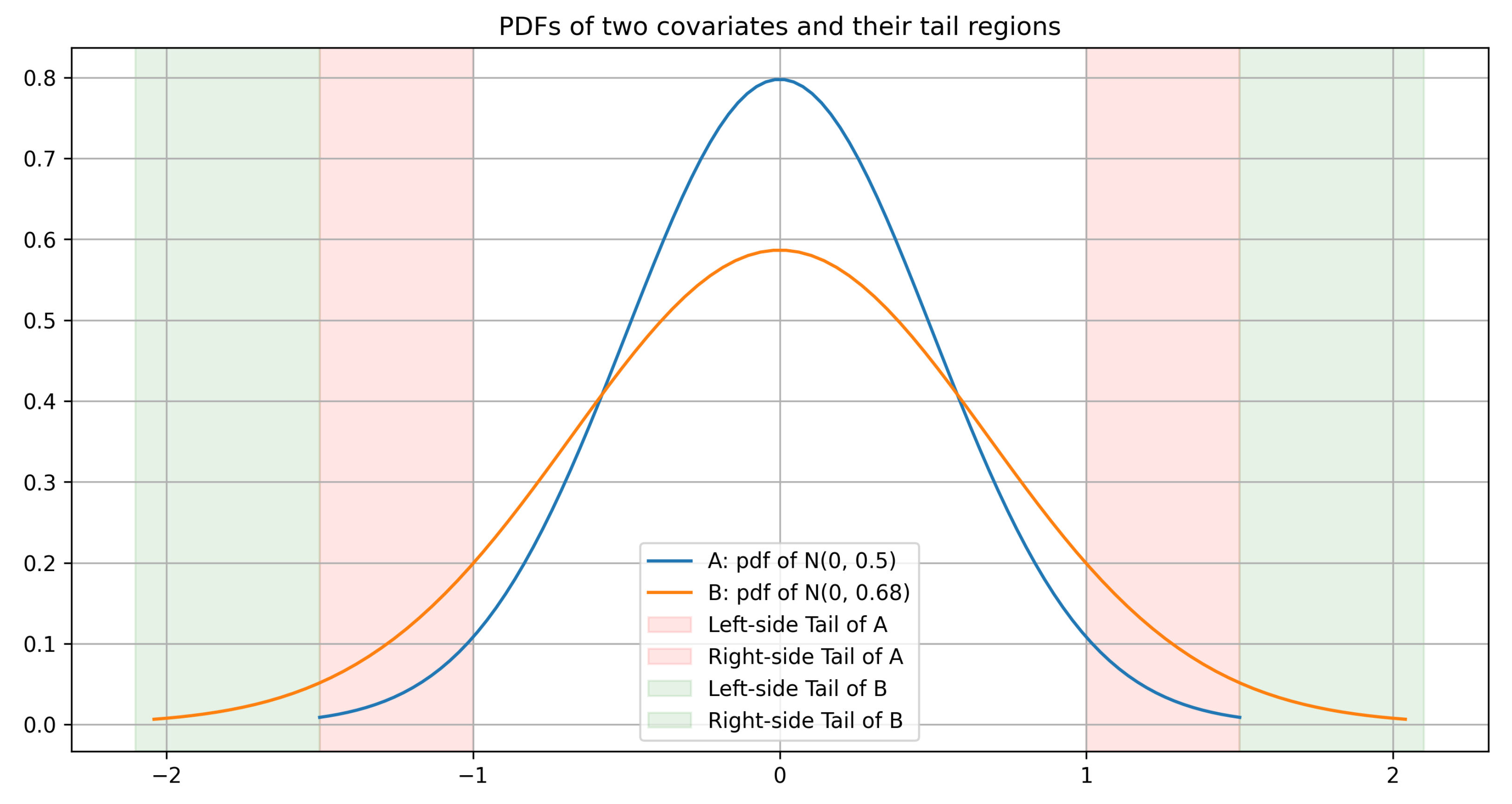
Working through Chapter 14 of Imbens & Rubin: the diagnostics for checking covariate overlap between treatment and control, with the formulas spelled out.
Joachims et al. reframe recommender systems as policies you can study with causal tools like inverse propensity weighting. My summary.
A single-page reference for causal inference methods and the load-bearing assumption behind each one, following Facure’s Causal Inference for the Brave and True.
Covariance is a dot product of centered variables. The short derivation that connects the statistical and geometric views.
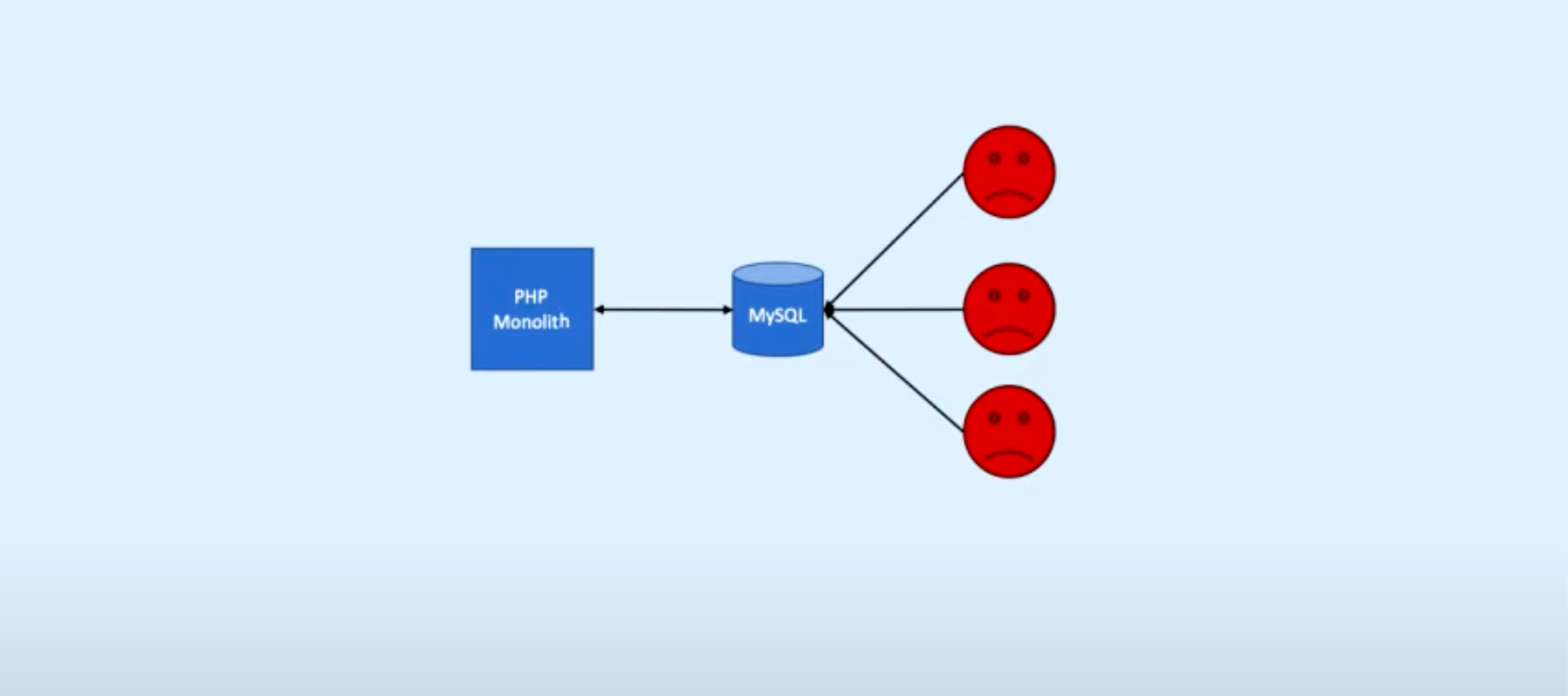
What happens after the ML proof-of-concept: the deployment patterns, tradeoffs, and failure modes of putting a model into production.
Notes on data pipeline patterns I picked up moving from ML work into data engineering, from a Chris Riccomini talk.
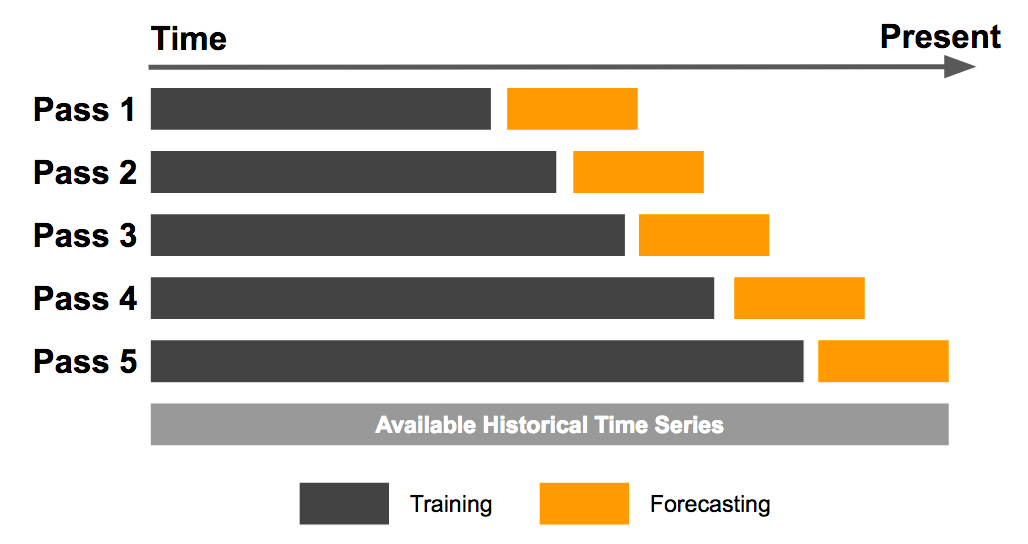
What I took away from Kaggle’s Jane Street Market Prediction competition: cross-validation, Keras tuning, and fast inference tricks.
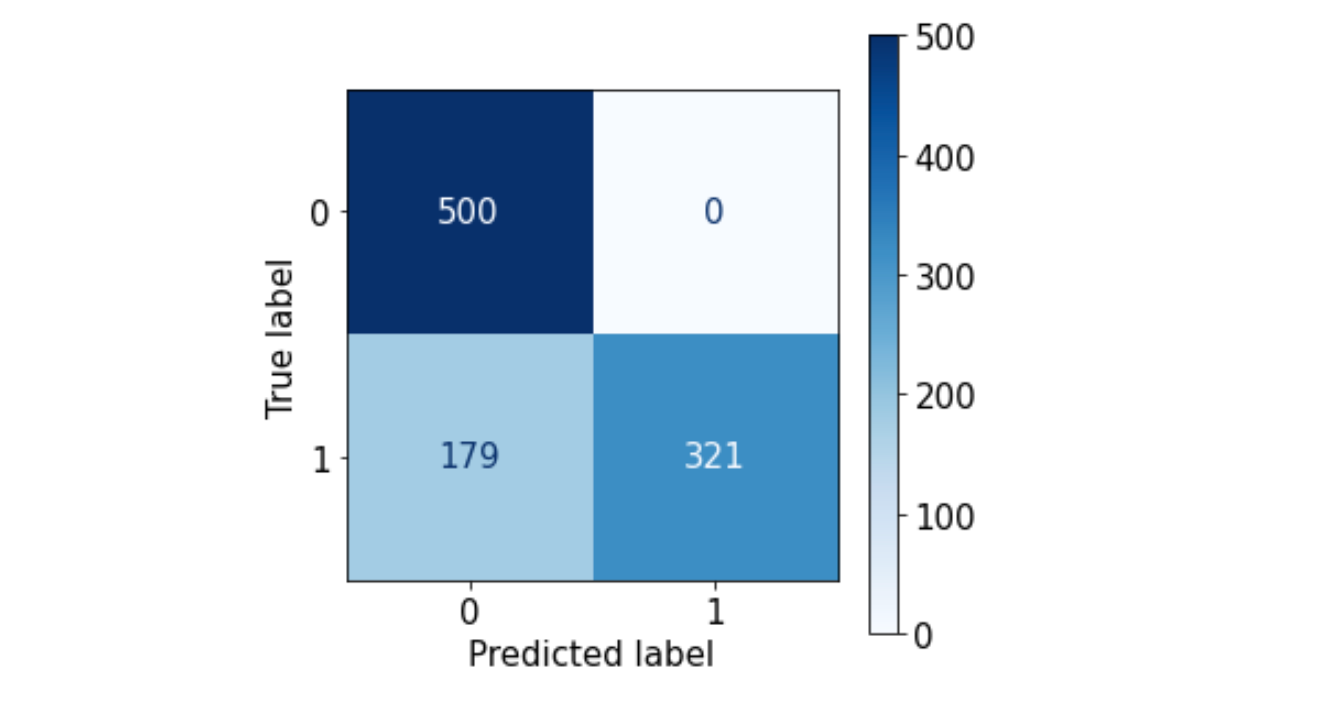
Binary classification gets called easy. A POC predicting campaign visits showed me where that assumption falls apart.